|
How to Work with Speech |
  
|
How to Work with Speech
|
How to Work with Speech |
|
Overview
MCL-Designer V4 allows you to develop speech applications, meaning, you can create a vocal interface between application and operator rather than rely solely on a traditional graphical interface, keyboard, scanner, etc.
It is possible to develop a project that only uses a speech interface (hear the device and speak into the device), which is particularly useful when the target device does NOT have a screen, or you can use a multi-modal approach - for instance, employ controls in a screen that can be configured to include speech attributes (ex: Input Keyboards, Input Barcodes, Buttons, CheckBoxes, Radio Buttons,etc.) and combine them with the use of a scanner, a keyboard, etc.
Speech related features can be managed in the project's properties (see Project Properties - Speech tab), in the existing speech processes (see Working with the Speech Processes Group) and within the controls that include speech attributes (see Speech in Controls).
The speech attributes provided by MCL-Designer V4 depend on three main components:
•ASR (Speech In) – Refers to Automatic Speech Recognizer. Consists of a phoneme based recognizer, with a language acoustic model (database).
•TTS (Speech Out) – Refers to Text-To-Speech. It is the software that converts computer text directly into spoken words.
•Word Lists - Tables defined by the developer that include the spoken word (phonetic data to be used for speech input recognition) and its corresponding value (data to be handled by the application).
Speech Recognition (via ASR)
Speech Recognition is performed by comparing the operator’s speech input data with the expected phoneme sequence, analyzing the resulting possibilities and providing the application with the best match.
The Recognizer Engine (ASR) responsible for the speech input's comparison analysis relies on two sources:
•The Language Model - It contains the defined language's linguistic rules and a collection of speech samples (recordings of speakers with different accents). Each supported language has its own Language Model.
•Word Lists - refer to the application's active vocabulary - lists of spoken words that the operator can speak at a given moment in the application. They are defined by the developer.
The diagram below illustrates the speech input recognition process:
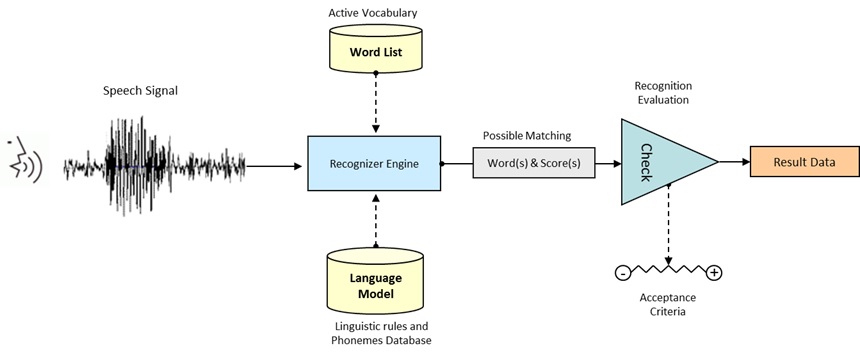
The phonetic data provided by the operator(Speech Signal) is put through the Recognizer Engine which uses the Language Model database and the existing Word Lists to find possible matches.
The resulting possibilities (Word(s) & Score(s)) are, then, evaluated (Recognition Evaluation) according to specific criteria (Acceptance Criteria) in order to come to the most accurate result (Result Data) that will be delivered to the application.
The flow of the speech application will, then, continue based on the speech command that was provided by the Speech Input Engine (ASR).
TTS (Text-to-Speech) Implementation
TTS implementation allows the use of multiple Speech Output voices within one application. In addition, it makes the use of different intonations possible. The TTS component is also available within MCL-Simulator.
TTS Prompts (Speech Output Sequences) are processed in two main steps:
a. Prompt Compilation
This is done prior to any new prompt playback. Its duration depends on the length of the prompt and CPU availability. To avoid a long compilation time, the system performs multiple partial prompt compilations. This way it starts playing one portion of the prompt while compiling the next one.
b. Prompt Playback
The system takes the compiled audio output and pushes it through the Codec chip. This is absolutely real time and CPU independent.
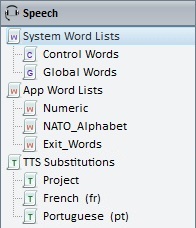
Word Lists
The development of speech applications implies the use/management of word lists (tables that contain the spoken word and the corresponding value).
Within MCL-Designer V4, all word lists are stored in the Speech module. This module provides default word lists and allows you to create additional word lists as needed.
![]() It is advisable that each speech input has its own word list containing the used speech commands in that context. This will prevent the construction of a dialog (between the system and the operator's speech input) containing unused words that can potentially affect speech recognition performance.
It is advisable that each speech input has its own word list containing the used speech commands in that context. This will prevent the construction of a dialog (between the system and the operator's speech input) containing unused words that can potentially affect speech recognition performance.
There are three word list categories:
•System Word Lists - There are two default System Word Lists:
Control Words - a list of spoken words and key codes or values that allow the operator to control predefined system functions (Speech Input Pause/Resume, TTS Volume, TTS Speed, Show User Profile, Calibration and Repeat Last Prompt). The phonetic value (spoken word) and key code or value for each function can be edited/defined by the developer.
Global Words - a list of spoken words defined by the developer with an associated key code or value also attributed by the developer. The purpose for this list is to allow the developer to create speech commands that are available across all speech inputs, meaning, they are used at project level (in processes or controls).
See System Word Lists.
•App Word Lists - This section contains the words that the operator can speak at particular points of the speech application (depending on the speech related process or control). These words are organized into word lists and can be grouped by type (ex: numeric, alphanumeric, etc.) or by function (ex: Yes/No, Shipment ID input, location input, etc.).
The default word lists (Numeric and NATO_Alphabet) can be edited and incremented with more information. If required, new App Word Lists can be added.
See App Words Lists.
•TTS Substitutions - This section enables the creation of "Word Substitution Tables". A TTS Substitution table is created to provide a phonetic variation to a selected spoken word. These substitutions are designed to help the operator's understanding of what he is hearing from the device.
See TTS Substitutions.
The speech dialog consists of speech input and speech output.
Speech output refers to what is prompted by the system. The main purpose for a prompt (= speech output) is to provide information or instructions regarding the operator's speech input.
Speech input refers to what is said by the operator, meaning, data/information that relates to the application's purpose.
The interaction between speech input and output is managed by defining the dialog's Sync mode.
The Sync mode determines when the user can start speaking (the sync mode is defined in controls/processes that can include word sequences with specific speech grammar).
There are several modes available:
•Sequential mode (end of last prompt)
The operator has to listen to the complete prompt before speaking.
Note that the recognizer will start to listen a few milliseconds before the current speech output finishes.
![]() Sequential is the mode used by default and the one recommended for most of the situations.
Sequential is the mode used by default and the one recommended for most of the situations.

SpI - operator speech input
SpO - system speech output/prompt
•Real Time mode (depends on active input object/cursor position)
The operator must consider the currently active input control. For instance, if there is a screen with multiple input controls that allow for speech input, the operator must listen to the prompt (= speech output) until the cursor jumps to the next intended input control to say the correct data.
In most cases, the Real Time mode allows the operator’s speech input to run sooner than the Sequential mode because there is no need to listen to the full prompt, only to follow the cursor to speak.
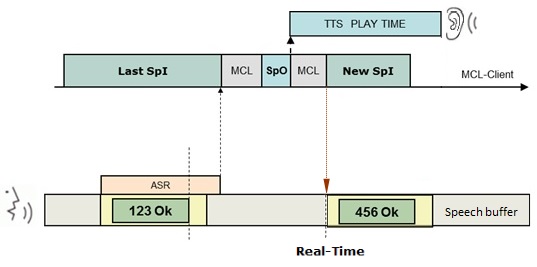
SpI - operator speech input
SpO - system speech output/prompt
•Anticipated mode (Start of last prompt)
The operator can speak as soon as the current speech output starts.
This mode is very useful when there are a lot of repetitive prompts because the operator does not have to wait for the end of each speech out to say a confirmation/speech input.

SpI - operator speech input
SpO - system speech output/prompt
•Continuous mode (End of last speech input)
The operator can speak multiple inputs in sequence.
This mode allows for a combination of multiple inputs, with specific grammar for each one, and fast speech input.

SpO - system speech output/prompt
Controls with Speech Attributes
Some controls can have speech properties (ex: Input Keyboard, Input Barcode, Button, CheckBox, Radio Button, etc.). Depending on the type of control (Data Input type control or Menu/Selection type control), it will be possible to define speech input or speech output scenarios. See Speech in Controls.
Processes associated to Speech
The Speech group of processes includes all speech related processes. These processes enable you to configure speech related features and, if required, you can use them to create a speech application without graphical interface (the operator only hears and talks into the device). See Working with the Speech Processes Group.
Refer to the MCL website for the list of support languages, devices and headsets:
Topics
This chapter covers the following topics:
Topic |
|---|